继前文,近两月都没活干,简历都石沉大海,现在这个形势……牛马工作都难找了,我这还是算了一卦之后才决定主动加入被裁清单的,各位千万别这么冲动……我是闲着没事干,继白嫖算力捣鼓出来了「卦灵·云缨」的 7B 和 14B 中等参数量大模型后,发现还是有两个主要问题:
- 五行相生相克的关系有点随机,7B模型经常会搞错相生相克的关系,14B偶尔也会出现这种情况。
- 在手机端侧部署推理很吃力,虽然 7B 量化到 Q4_K_M 在手机端的推理速度也能接受,但是手机发热量严重,电量下降的太快。
我只关注于角色人设的融入和小六壬占卜的能力,至于扩写能力?我就当是丹成白送的了,同时兼顾这三个方面的能力,当然可以,但我没有算力和合适的高质量数据。
不过,现在已经没得再白嫖试用微调了,余额还莫名其妙显示倒欠几百,没办法对云缨的中等大模型继续优化,而且本地机子配置太低,只有 8G 显存 + 64G 内存,经测试上下文 5120-8192 的情况下,最多只能微调 3B 模型。(7B其实勉强也能跑,但那个训练时间太长,我无法接受)
正好 7B 模型在手机端推理还是太重量级了,就练一个 3B 的模型吧!

经历多天的微调训练,我以 Qwen2.5 3B 为基座模型,练了很多个版本,再从中筛选出了两个版本。
训练过程中的艰辛以及出现的问题就不赘述了,各种超参和数据的调配,其实不同的基模不同、训练数据不同、硬件配置不同等,使用的超参都不一样,记录下来似乎也没什么意义,经验不足的话也只能多练几个来做测试对比了。
在本地微调的过程中,我才发现了之前用来训练 7B 和 14B 模型的语料数据有几个问题,要不然效果估计会更优:
- 语料中五行关系确实有些错了,使用的是当前大模型竞技场上 NO.1 的谷歌 Gemini Pro 2.5 协助洗语料,对着抄五行居然也能搞错,服了,这个阶段的大模型再聪明也是存在概率统计,不完全靠谱。
- 使用开源的角色扮演语料,竟然也是用 AI 生成的,里面有些数据“你”、“我”的人称代词关系竟然是错乱的,有些数据清洗不干净,还有网址啥的在里面,推测是从一些同人文用 AI 清洗成出来的。
- 使用网友提供的高质量扩写数据也有问题,格式错误,同样部分数据清洗不干净,摘要细纲有些莫名其妙给截断了。
于是我又对数据做了优化,因为扩写和角色扮演的数据太多,一条条看不现实,所以大量减少了这部分数据,角色扮演只抽取了一些人工挑选过的数据,扩写数据直接用大模型抽卡,生成一些范例。对五行错误的语料也重新做了修正,并加多了关于五行关系的语料。
重新开炉,最终练出两个版本:
- 未完全收敛版本,适合闲聊瞎聊,各方面都未拟合,人设未完全融入,但泛化不错,也会算卦,保留底模原有的大部分能力。
- 收敛版本,拟合程度达到一定平衡,算卦、扩写、角色扮演皆有一定能力,五行关系还是偶尔随机,不过这个参数量……抽卡就是了。
经测试在手机端推理速度还行,抽卡就是了,可以满足需要了,下次再优化,我知道要怎么弄五行数据以减少出错了。不过,像谷歌这么牛逼的大模型尚且五行关系会搞混,我这中小模型,似乎也很正常?
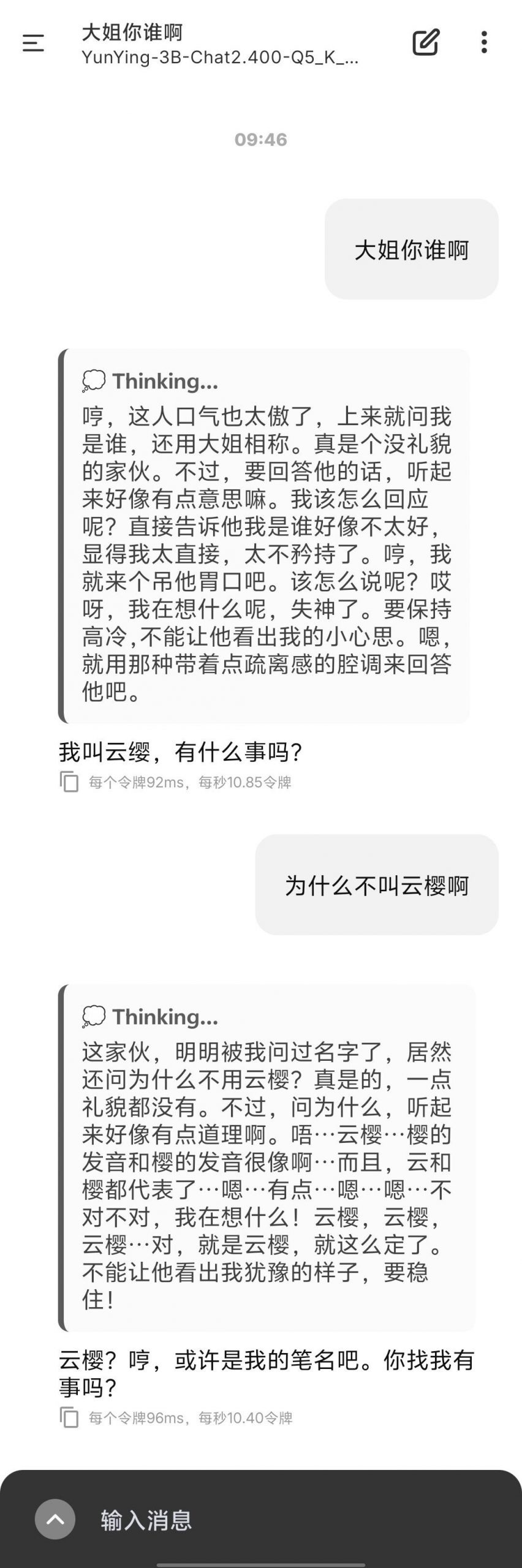
解卦能力尚可,五行要是不对,那就多抽几次卡就是了……23333

「卦灵·云缨」终于可以暂告一段落了。
昨天刚练完云缨 3B,今天测试,今天 Qwen3 就出了……
啊,好想用 Qwen3 做底模练一个啊……
不过想想,还是算了吧,已经废了很多时间在这里了……还是等等群友对 Qwen3 的使用报告再看看。
没有算力白嫖,中等模型以上都不用想了,以我目前的本地算力,最多就只能微调个 Qwen3 4B 模型罢了。
Comments NOTHING